
Dynamic Variability in Speech: A Forensic Phonetic Study of British English.

ESRC award no. RES-000-23-1248
October 2005 - September 2009
More and more court cases involve the need to establish the speaker of some recorded speech - a hoax emergency call, a fraudulent phone transaction, an obscene voicemail, and so on. Voices, however, are not like fingerprints. A person's voice varies, depending for instance on tiredness, how loud and fast he or she is speaking, and many other factors. Despite this, there is a core of similiarity in an individual's speech. This project will record 100 speakers of the same accent in different speaking styles, and analyse their speech to determine how far they can be discriminated and what the best measures are for characterising their speech. The effects of using the telephone on an individual's speech will also be analysed.
In particular it will explore two ideas. The first is that speakers' 'vocal signatures' lie in the rapid, transitional movements of the speech organs between sounds. The second idea is that within a homogeneous speech community the sounds which are most likely to differ between speakers are those which are undergoing a rapid change in pronunciation over time. The results will show which parts of the speech signal forensic speaker identification should focus on. The project will also provide a carefully controlled large-scale speech database for further research.
The project is funded by the UK Economic and Social Research Council. We are also grateful to BT for sponsorship relating to the telephone transmission aspect of the investigation.
The DyViS Database - click here to access.
The database provides:
- speech recordings100 male speakers of Standard Southern British English aged 18-25
- speaking in a variety of styles
- simulation of forensic conditions
- approximately 1.25 hours of speech per speaker
- 20 speakers recalled for repeat of reading tasks after 2 months
Read more about the database below.
The complete database is available, as .wav files, associated Praat .TextGrid files with an orthographic transcript of the target speakers' turns in the spontaneous tasks, and the materials used in making the recordings, from the UK Data Service here.
Users have to register with the UK Data Service.
Forensic Speaker Identification
Criminal investigations rely increasingly on identifying individuals based on the unique traces they leave behind (Saferstein 2001: 62-65, White 1998: 7-8). Fingerprints have long been used for this purpose, and modern techniques can use an individual’s genetic make-up in the form of DNA to establish involvement in criminal activity. Recently, an intruder was identified from dandruff left at the crime scene (Wainwright 2004). A growing number of criminal cases involve the perpetrator’s trace taking the form of a recorded sample of speech (Nolan 1991, Künzel 1994). Sometimes an incriminating sample of speech is recorded over the telephone, e.g. a ransom demand, or a bomb threat. A phonetician carries out the task of ‘forensic speaker identification’, that is, compares the speech on the incriminating recording with samples of speech from a suspect, with a view to identifying the perpetrator or eliminating the suspect (French 1994).
In everyday life, speakers have no problem identifying familiar voices and even distinguishing between voices they have heard only one or two times (Nolan 1997: 744, Rose 2002: 10, Rose and Duncan 1995, cf. Foulkes and Barron 2000). Informal observation suggests that a voice could be as unique to an individual as his or her DNA, however it has not been proved that voices are unique, and there is no known set of criteria that can determine speaker identity with 100% certainty (French 1990: 62, Nolan 1997: 755, Nolan 2001). The lack of research and data about the distribution of speech features in the population as a whole severely limits the reliability of forensic speaker identification. Cases involving phonetic evidence are usually sensitive and controversial, so it is important that phoneticians have access to a knowledge base as broad and as detailed as possible.
Are voices unique?
The concept of each individual possessing a single ‘voice’ is not as straightforward as it seems since, unlike the fixed pattern of a fingerprint or an individual’s DNA sequence, the voice is subject to an immense range of variability (Nolan 1991: 486, 1997: 748-749). While the physical dimensions of a speaker’s vocal tract impose some limits on the speech output a speaker can produce (Nolan 1983: 27-28, 59, Rose 2002: 300-302, Stevens 1971), speakers vary their voices depending on their familiarity with the interlocutor, the degree of formality of the situation, the level of background noise, and so on. Speakers exploit the flexibility of their voices to express different emotions or even to disguise their voices (Künzel 2000, Masthoff 1996). A person’s voice also changes with his or her state of health, for example catching a cold or a sore throat (Braun 1995, Rose 2002: 299-300). These sources of variation all complicate speaker identification (French 1994: 178-179, Nolan 1997: 748, Nolan 2001, Rose 2002: ch.10).
A major methodological problem facing approaches to speaker identification is the lack of population data. Most phonetic studies involve 5 to 10 speakers at most, depending on the techniques employed (cf. Fant, Kruckenberg and Nord 1991: 521, Westbury, Hashi and Lindstrom 1998). Acoustic studies with a forensic or sociolinguistic focus may look at up to 30 speakers, but large-scale data are not available (Nolan 1997: 767). This lack of population statistics means that it is not possible to assess adequately the extent to which any given phonetic variable might contribute to the identification of an individual from amongst a population of speakers, and in particular whether such speaker-discriminating information is preserved under forensic conditions.
How unique is speaker variability?
A phonetic variable which exhibits idiosyncratic features may also be subject to pressures from variation within the language system. Language is constantly changing in some respect, and at any given moment some sounds will be more stable than others. Although variability between socially-determined groups is the primary focus of sociolinguistic research, relatively little attention has been paid to microvariability at the level of the individual (Johnstone 1996). Research is beginning to address this aspect of linguistic variation (e.g. Wolfram and Beckett 2000, Beckett 2003), but there is a pressing need for further detailed investigations. Understanding the extent of potential variability of a sound within the language system is important in identifying speaker-specific characteristics of that variable. Furthermore, speakers may exhibit individual patterns of usage across a range of variables thereby providing an additional source of speaker-characterising information. A data set comprising recordings from a large number of speakers, all members of the same speech community, is needed to investigate these issues.
Rationale for the DyViS Project
The DyViS project offers a novel approach to the characterisation of speakers. Our unifying conceptual theme is the dynamism of speech, dynamism being interpreted in two ways. The first concerns the rapidly changing parts of the speech signal known broadly as ‘transitions’. Our assumption is that the speech signal contains linguistically determined targets (canonically thought of as the ‘centres’ of segments), linked by transitions. We hypothesise that the targets are highly constrained by the shared language system, and therefore there is greater scope for speaker-idiosyncrasy in the transitions, these being determined by the interaction of the specific organic endowment of the speaker, the adjacent linguistic targets, and the speaker’s learned solution to moving between those targets. The second interpretation of dynamism concerns linguistic change. Our hypothesis is that variation in linguistic targets between speakers will be greatest for sounds undergoing rapid change. Even speakers of the same generation will vary in the extent to which they are in the vanguard of change in particular sound, or lag behind the change. The linguistic phonetic aspect of the project therefore focuses on a selection of sounds known to be rapidly changing. The speech variety selected for this project is Standard Southern British English (SSBE).
DyViS has the following research aims:
1) To test the practicality of ‘speaker-space’ for distinguishing members of a large population of speakers.
2) To quantify articulatory-acoustic dynamic features for individual speakers.
3) To test diachronic change as a source of speaker idiosyncrasy.
4) To make available a speech database of Standard Southern British English (SSBE) for wider use by other researchers, forensic phonetic practitioners, and other interested persons.
1. Testing the practicality of ‘speaker space’
The notion of a multidimensional ‘speaker-space’ has been discussed theoretically (Nolan 1991: 486-487, 1997: 746, see also Rose 2002: 10-16, Rose 2003b: 3053-3059), but not tested for a large population of speakers. The notion of ‘speaker-space’ was devised by Nolan (1991) as a way of accounting for variation within an individual’s speech, as well as variation between speakers. For a given phonetic variable, a single speaker can exhibit a range of values, and it is not uncommon for these ranges to overlap for different speakers (Nolan 1983: 59-60, Nolan 1997: 748, Rose 2002: 12). Nolan’s multidimensional ‘speaker-space’ comprises a large number of phonetic dimensions along which speakers vary. Speakers each occupy a region of this space, sometimes overlapping with one another along particular dimensions. If the hypothesis that voices are unique is true, each individual speaker could be characterised by a unique region of this multi-dimensional space. To establish unique regions for all individuals, sufficient phonetic variables are needed to distinguish every speaker from every other in their values for at least one variable. Such a construction would require a large number of variables, and these variables should exhibit low within-speaker and high between-speaker variation. Various speech variables have been demonstrated to be useful in this regard; these include average fundamental frequency (French 1990: 44-48, Wolf 1972, but cf. Braun 1995, Boss 1996), formant frequency measurements at defined time-points (e.g. Bachorowski and Owren 1999, Bosch 2003, Jessen 1997, Kinoshita 2001: ch. 4-6, Nolan 1983: ch. 3, Paliwal 1984), aspects of hesitation markers (Foulkes, Carrol and Hughes 2004, Pätzold and Simpson 1995), durational properties (e.g. van den Heuvel, Rietveld and Cranen 1994) and features of intonation (e.g. Nolan 2002a). However the effectiveness of a combination of such variables for distinguishing speakers among a large population is yet to be evaluated. DyViS thus aims to investigate how far it is possible, in practical terms, to distinguish all or nearly all speakers in a large population using familiar phonetic variables, and which variables are most valuable.
2. Quantifying dynamic features of speech encoding speaker identity
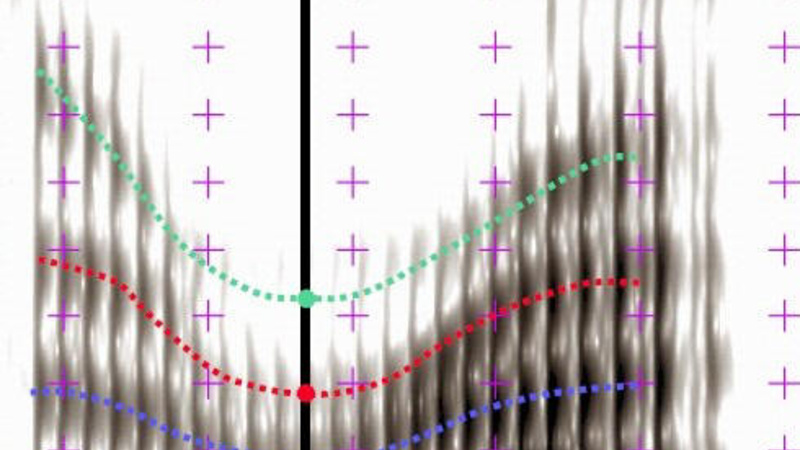
DyViS will build on a recent programme of doctoral research conducted by Kirsty McDougall which investigates speaker-characterising properties of dynamic (time-varying) features of the speech signal (McDougall 2005). Most research on between-speaker differences has focused on instantaneous or average speech properties (cf. Barlow and Wagner 1998, Nolan 2002b: 81-82), but these are insufficient to characterise speakers uniquely. Dynamic features are likely to furnish more fine-grained speaker-specific differences because they reflect the movement of a person’s speech organs. Just as people exhibit their own personal styles for walking, running and other skilled motor activities (cf. Runeson 1985, Sheridan 1985), they make their gestures for speech in individual ways. If speech is thought of as a series of articulatory targets, it is possible that although the speech of different speakers may exhibit the same or very similar acoustic properties at moments when targets are achieved, there is considerable scope for individual variation in moving between the targets (see also McDougall 2006).
In recent experiments, McDougall has demonstrated that dynamic features of formant frequencies have the potential to make a crucial contribution to the characterisation of a speaker (McDougall 2002, 2003a, 2004a, 2004b). Formant frequencies are highly relevant to speaker characterisation, since they are determined by both the dimensions of a speaker’s vocal tract and the way the vocal organs are configured to produce each sound (Nolan 2002b: 78, Nolan and Grigoras 2005). McDougall found that considerable speaker-specific information is present in the formant contours accompanying the transitions between the targets for a speech sound or sequence of sounds, both in studies of the diphthong /aɪ/ in Australian English (McDougall 2002, 2003a, 2004b), and vowel-/r/-vowel sequences in British English (McDougall 2004a). The degree of speaker discrimination achieved is a marked improvement on that attained by simply measuring formant frequencies at the temporal midpoint for each segment, the typical approach in previous research.
The experiments from McDougall’s Ph.D. revealed that formant dynamics are a valuable source of speaker-specific information, for example, classification rates of 88-95% were yielded for a small group of speakers by discriminant analyses on measurements from the F1, F2 and F3 contours of /aɪ/ (McDougall 2002, 2004b). However, the technique for describing formant contours in this work essentially used a series of cumbersome instantaneous measurements. A method that captures the defining aspects of the contours is required to compare large numbers of speakers efficiently. DyViS aims to develop a new technique to parameterise each formant curve, yielding an economical descriptor which elegantly captures the dynamics of this feature for individual speakers.
The DyViS project will enable this new technique to be tested on a much larger population than in the doctoral study and on a wider range of sound sequences. DyViS will expand McDougall's work on the formant dynamics of /aɪ/ and intervocalic /r/ to explore the speaker-characterising potential of a variety of combinations of English vowels and other sonorant segments. The study will also examine how well speaker-specific properties of formant dynamics are preserved across different recording sessions and under different conditions of linguistic context and speaking situation. This is extremely important for forensic speaker identification as the circumstances under which the incriminating and suspect samples are recorded usually differ (e.g. crime-related phone call versus police interview).
3. Testing diachronic change as a source of speaker idiosyncrasy
Speech is dynamic in terms of transitions between sounds, and also in the sense that the language system is constantly in flux. Some linguistic variation leads to change as new realisations of existing contrasts become established, as old contrasts merge, and as new contrasts are formed. At any point in time, certain sounds are changing, while others appear more stable. This kind of dynamism can be referred to as diachronic dynamism.
There are two ways in which this diachronic dynamism may be useful for identifying individual speakers. Firstly, particular speakers from the same social group may differ in terms of their realisations of variables which are undergoing change. One speaker may exhibit a more conservative or a more novel realisation than others. Although in the longer term a particular change would be expected to characterise all members of a speech community, in the shorter term patterns of usage may be valuable in distinguishing different speakers (Moosmüller 1997).
Furthermore, individual speakers may not consistently use one particular realisation of a changing variable, showing different rates of usage of novel versus conservative forms. For example, a speaker may use a particular realisation in 35% of possible cases, or only in certain contexts, whereas others show different usage patterns (Loakes and McDougall 2004). These usage rates may relate to the extent to which speakers have adopted variable patterns of phonological conditioning or lexical diffusion across the speech community as a whole. These patterns of usage may allow different individuals to be distinguished from one another (Butterfint 2004).
DyViS will analyse the speaker-distinguising potential of phonetic variables thought to be currently undergoing change in SSBE. The vowel /u/ is being realised further forward in the vowel space (Harrington, Palethorpe and Watson 2000), and /əʊ/ appears to be produced with a similarly fronted realisation of the diphthongal endpoint /ʊ/. The realisations of these vowels will be compared with those of stable vowels, such as /i/ and /ɔ/ (Hawkins and Midgley 2005). For consonants, the occurrence of ‘labiodental’ /r/ is said to be increasing in many non-standard varieties of British English, (cf. Lindsey and Hirson 1999, Trudgill 1999, Foulkes and Docherty 2000, 2001). The DyViS project aims to determine what proportion of SSBE speakers exhibit ‘labiodental’ forms of /r/, and the degree of variation between speakers present in these realisations of /r/. In addition to the major aim of using patterns of phonological variability to characterise individuals, these data may inform current ideas about the role of language use and lexical frequency in patterns of diachronic change.
4. Developing a forensic phonetic database for SSBE
The DyViS project will offer a database of read and spontaneous speech collected from a large number of individuals within a single speech community, recorded under studio and telephone quality conditions. The participants will be male speakers of SSBE, aged 18-25. 100 speakers will be recorded, a substantially larger number of participants than in previous forensic phonetic studies of English.
The following data will be collected from each subject:
1. simulated police interview (studio quality)
2. telephone conversation with investigator – interview debrief (recorded on two lines – studio and telephone quality)
3. controlled data (read) – reading passage and focus sentences (studio quality)
Some speakers will undertake a second recording session containing similar tasks to enable analysis of non-contemporaneous variation, a major concern in forensic cases.
The speech files will be accompanied by orthographic labelling. Full orthographic transcripts of spontaneous data and lists of read sentences will also be provided.
The database will be made publicly available at the conclusion of the project.
References
Anderson, A. H., M. Bader, E. G. Bard, E. Boyle, G. Doherty, S. Garrod, S. Isard, J. Kowtko, J. McAllister, J. Miller, C. Sotillo, H. S. Thompson and R. Weinert (1991) 'The HCRC Map Task Corpus', Language and Speech 34(4): 351-366.
Bachorowski, J.-A. and M. J. Owren (1999) 'Acoustic correlates of talker sex and individual talker identity are present in a short vowel segment produced in running speech', Journal of the Acoustical Society of America 106(2): 1054-1063.
Barlow, M. and M. Wagner (1998) 'Measuring the dynamic encoding of speaker identity and dialect in prosodic parameters', in R. H. Mannell and J. Robert-Ribes (eds.), Proceedings of the 5th International Conference on Spoken Language Processing, 30 November - 4 December 1998, Sydney: Australian Speech Science and Technology Association, 81-84.
Beckett, D. (2003) 'Sociolinguistic individuality in a remnant dialect community', Journal of English Linguistics Vol. 31(No. 1): 3-33.
Bosch, J. C. (2003) 'Acoustic study of the vowel formant frequencies and F0: a contribution to Catalan forensic phonetics', in M. J. Solé, D. Recasens and J. Romero (eds.), Proceedings of the 15th International Congress of Phonetic Sciences, 3-9 August 2003, Barcelona: Causal, 687-690.
Boss, D. (1996) 'The problem of F0 and real-life speaker identification: a case study', Forensic Linguistics 3(1): 155-159.
Braun, A. (1995) 'Fundamental frequency - how speaker-specific is it?' in A. Braun and J.-P. Köster (eds.), Studies in Forensic Phonetics: Beiträge zur Phonetik und Linguistik 64, 9-23.
Butterfint, Z. (2004) Individuality in Phonetic Variation: An Investigation into the Role of Intra-Speaker Variation in Speaker Discrimination. Ph.D. Dissertation, Manchester University.
Fant, G., A. Kruckenberg and L. Nord (1991) 'Prosodic and segmental speaker variations', Speech Communication 10: 521-531.
Foulkes, P. and A. Barron (2000) 'Telephone speaker recognition amongst members of a close social network', Forensic Linguistics 7(2): 180-198.
Foulkes, P., G. Carrol and S. Hughes (2004) 'Sociolinguistic and acoustic variability in filled pauses'. Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, 28-31 July 2004, Helsinki.
Foulkes, P. and G. J. Docherty (2000) 'Another chapter in the story of /r/: 'Labiodental' variants in British English', Journal of Sociolinguistics 4(1): 30-59.
Foulkes, P. and G. J. Docherty (2001) 'Variation and change in British English /r/', 'r-atics: Sociolinguistic, Phonetic and Phonological Characteristics of /r/', Etudes et Travaux 4: 27-43.
French, P. (1990) 'Acoustic phonetics', in J. Baldwin and P. French (eds.), Forensic Phonetics. London: Pinter, 42-63.
French, P. (1994) 'An overview of forensic phonetics with particular reference to speaker identification', Forensic Linguistics 1(1): 169-181.
Harrington, J., S. Palethorpe and C. I. Watson (2000) 'Monophthongal vowel changes in Received Pronunciation: an acoustic analysis of the Queen's Christmas broadcasts', Journal of the International Phonetic Association 30(1): 63-78.
Hawkins, S. and J. Midgley (2005) 'Formant frequencies of RP monophthongs in four age-groups of speakers', Journal of the International Phonetic Association 35(2): 183-199.
Jessen, M. (1997) 'Speaker-specific information in voice quality parameters', Forensic Linguistics 4(1): 84-103.
Johnstone, B. (1996) The Linguistic Individual: Self-Expression in Language and Linguistics. Oxford: Oxford University Press.
Kinoshita, Y. (2001) Testing Realistic Forensic Speaker Identification in Japanese: A Likelihood Ratio-Based Approach Using Formants. Ph.D. Dissertation, Australian National University.
Künzel, H. J. (1994) 'On the problem of speaker identification by victims and witnesses', Forensic Linguistics 1(1): 45-57.
Künzel, H. J. (2000) 'Effects of voice disguise on speaking fundamental frequency', International Journal of Speech, Language and the Law 7(2): 149-179.
Lindsey, G. and A. Hirson (1999) 'Variable robustness of nonstandard /r/ in English: evidence from accent disguise', Forensic Linguistics 6(2): 278-288.
Loakes, D. and K. McDougall (2004) 'Frication of /k/ and /p/ in Australian English: inter- and intra-speaker variation', in S. Cassidy, F. Cox, R. Mannell and S. Palethorpe (eds.), Proceedings of the 10th Australian International Conference on Speech Science and Technology, 8-10 December 2004, Sydney: Australian Speech Science and Technology Association, 171-176.
Masthoff, H. R. (1996) 'A report on a voice disguise experiment', Forensic Linguistics 3(1): 160-167.
McDougall, K. (2002) 'Speaker-characterising properties of formant dynamics: a case study', in C. Bow (ed.) Proceedings of the 9th Australian International Conference on Speech Science and Technology, 3-5 December 2002, Melbourne: Australian Speech Science and Technology Association, 403-408.
McDougall, K. (2003) 'Individual differences in the formant dynamics of vowels at different levels of stress', in M. J. Solé, D. Recasens and J. Romero (eds.), Proceedings of the 15th International Congress of Phonetic Sciences, 3-9 August 2003, Barcelona: Causal, 1611-1614.
McDougall, K. (2004a) 'Between-speaker variation in formant dynamics associated with intervocalic /r/'. Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, 28-31 July 2004, Helsinki.
McDougall, K. (2004b) 'Speaker-specific formant dynamics: an experiment on Australian English /aɪ/', International Journal of Speech, Language and the Law 11(1): 103-130.
McDougall, K. (2005) The Role of Formant Dynamics in Determining Speaker Identity. Ph.D. Dissertation, University of Cambridge.
McDougall, K. (2006) 'Dynamic features of speech and the characterisation of speakers: towards a new approach using formant frequencies.' International Journal of Speech, Language and the Law 13.1: 89-126.
Mokhtari, P. and F. Clermont (1996) 'A methodology for investigating vowel-speaker interactions in the acoustic-phonetic domain', in P. McCormack and A. Russel (eds.), Proceedings of the 6th International Conference on Speech Science and Technology, 6-8 December 1994, Adelaide: Australian Speech Science and Technology Association, 127-132.
Moosmüller, S. (1997) 'Phonological variation in speaker identification', Forensic Linguistics 4(1): 29-47.
Nolan, F. (1983) The Phonetic Bases of Speaker Recognition. Cambridge: Cambridge University Press.
Nolan, F. (1991) 'Forensic phonetics', Journal of Linguistics 27: 483-493.
Nolan, F. (1997) 'Speaker recognition and forensic phonetics', in W. J. Hardcastle and J. Laver (eds.), The Handbook of Phonetic Sciences. Cambridge: Cambridge University Press, 744-767.
Nolan, F. (2001) 'Speaker identification evidence: its forms, limitations and roles', in T. Salmi-Tolonen, R. Foley and I. Tukiainen (eds.), Proceedings of the Conference "Law and Language: Prospect and Retrospect", 12-15 December 2001, Department of Linguistics, University of Lapland, Levi, Finnish Lapland: Rovaniemi, CD-ROM.
Nolan, F. (2002a) 'Intonation in speaker identification: an experiment on pitch alignment features', Forensic Linguistics 9(1): 1-21.
Nolan, F. (2002b) 'The "telephone effect" on formants: a response', Forensic Linguistics 9(1): 74-82.
Nolan, F. and C. Grigoras (2005) 'A case for formant analysis in forensic speaker identification', International Journal of Speech, Language and the Law 2(2): 143-173.
Paliwal, K. K. (1984) 'Effectiveness of different vowel sounds in automatic speaker identification', Journal of Phonetics 12: 17-21.
Pätzold, M. and A. Simpson (1995) 'An acoustic analysis of hesitation particles in German', in K. Elenius and P. Branderud (eds.), Proceedings of the 13th International Congress of Phonetic Sciences, 13-19 August 1995, Stockholm: KTH and Stockholm University, vol. 3, 512-515.
Rose, P. (2002) Forensic Speaker Identification. London: Taylor and Francis.
Rose, P. (2003) 'The technical comparison of forensic voice samples', in I. Freckleton and H. Selby (eds.), Expert Evidence. Sydney: Lawbook Co., Chapter 99.
Rose, P. and Duncan (1995) 'Naive auditory identification and discrimination of similar voices by familiar listeners', Forensic Linguistics 2(1): 1-17.
Runeson, S. (1985) 'Perceiving people through their movements', in B. D. Kirkcaldy (ed.), Individual Differences in Movement. Lancaster: MTP Press, 43-66.
Saferstein, R. (2001) Criminalistics: An Introduction to Forensic Science. Upper Saddle River, New Jersey: Prentice Hall.
Sheridan, M. R. (1985) 'Individual differences in voluntary movement', in B. D. Kirkcaldy (ed.), Individual Differences in Movement. Lancaster: MTP Press, 3-26.
Stevens, K. N. (1971) 'Sources of inter- and intra-speaker variability in the acoustic properties of speech sounds', in A. Rigault and R. Charbonneau (eds.), Proceedings of the 7th International Congress of Phonetic Sciences, 22-28 August 1971, Montreal: Mouton, 206-232.
Trudgill, P. (1999) 'Norwich: endogenous and exogenous linguistic change', in P. Foulkes and G. Docherty (eds.), Urban Voices: Accent Studies in the British Isles. London: Arnold, 124-140.
van den Heuvel, H., T. Rietveld and B. Cranen (1994) 'Methodological aspects of segment- and speaker-related variability. A study of segmental durations in Dutch.' Journal of Phonetics 22: 389-406.
Wainwright, M. (2004) ''Robber's dandruff costs him 15 years in jail'', The Guardian, Tuesday 23 November 2004.
Westbury, J. R., M. Hashi and M. J. Lindstrom (1998) 'Differences among speakers in lingual articulation for American English /ɹ/', Speech Communication 26: 203-226.
White, P. (1998) Crime Scene to Court: The Essentials of Forensic Science. Cambridge: The Royal Society of Chemistry.
Wolf, J. J. (1972) 'Efficient acoustic parameters for speaker recognition', Journal of the Acoustical Society of America 51(6/2): 2044-2056.
Wolfram, W. and D. Beckett (2000) 'The role of the individual and group in Earlier African American English', American Speech 75(1): 3-33.
|
Principal Investigator: |
Senior Research Associate: |
|
Research Associate: |
Research Assistant: |
|
Phonetics Laboratory Technician |
Project design also by |
Introducing the DyViS Database: a large-scale forensically oriented speech corpus
Click here to access the DyViS Database.
- 100 male speakers of Standard Southern British English aged 18-25
- speaking in a variety of styles
- simulation of forensic conditions
- approximately 1.25 hours of speech per speaker
- 20 speakers recalled for repeat of reading tasks after 2 months
Press release available here at the University of Cambridge Enterprise website.
1. Police interview
The speaker is interrogated in a mock investigation concerning a drug trafficking incident. Target words include many SSBE vowels in contexts convenient for measurement. Speech is constructed spontaneously using visual stimuli, including prompts to lie.
2. Telephone conversation with accomplice
Recording at studio quality plus intercepted external BT landline. Subject speaks with his accomplice, Robert Freeman, who elicits the same target words during a debriefing of the interview.
3. News report (reading)
The subject reads a news report of the alleged crime which he has committed. The same target words are used for comparison between conversational and read styles.
4. Controlled sentences (reading)
A large number of sentences with many SSBE monophthongs and diphthongs in nuclear non-final position.
- also /ju:/ and /wi:/ sequences
- 6 repetitions
All speakers are anonymous and talk about an imagined scenario, and so there are no problems with data protection. The database is available for all research purposes.
The recordings are useful for instance
- for research into individual speaker characteristics and forensic speaker identification
- for the investigation of spoken discourse
- for early-stage student projects (which e.g. can exploit the 'ready-made' sentences)
- as the most extensive resource available of current-day 'RP'
Journal articles
Duckworth, M., McDougall, K., de Jong, G., & Shockey, L. (2011). 'The consistency of formant measurements in high quality audio data: the effect of agreeing measurement procedures.' International Journal of Speech, Language and the Law 18.1: 35-51.
Nolan, F., McDougall, K., de Jong, G., & Hudson, T. (2009). 'The DyViS database: style-controlled recordings of 100 homogeneous speakers for forensic phonetic research.' International Journal of Speech, Language and the Law 16.1: 31-57.
Lawrence, S., Nolan, F., & McDougall, K. (2008). 'Acoustic and perceptual effects of telephone transmission on vowel quality.' International Journal of Speech, Language and the Law 15.2: 159-190.
Book chapter
de Jong, G., McDougall, K., & Nolan, F. (2007). 'Sound change and speaker identity: an acoustic study'.
In: Christian Müller (ed.). Speaker Classification II: Selected Papers. Berlin: Springer. 130-141.
Conference Proceedings
de Jong, G., McDougall, K., Hudson, T., & Nolan, F. (2007). 'The speaker-discriminating power of sounds undergoing historical change: a formant-based study'.
In: J. Trouvain & W. Barry (eds.). Proceedings of the 16th International Congress of Phonetic Sciences, 6-10 August 2007, Saarbrücken, 1813-1816. [pdf]
Hudson, T., de Jong, G., McDougall, K., Harrison, P., & Nolan, F. (2007). 'F0 statistics for 100 young male speakers of Standard Southern British English'.
In: J. Trouvain & W. Barry (eds.). Proceedings of the 16th International Congress of Phonetic Sciences, 6-10 August 2007, Saarbrücken, 1809-1812. [pdf]
McDougall, K., & Nolan, F. (2007). 'Discrimination of speakers using the formant dynamics of /u:/ in British English'.
In: J. Trouvain & W. Barry (eds.). Proceedings of the 16th International Congress of Phonetic Sciences, 6-10 August 2007, Saarbrücken, 1825-1828. [pdf]
Nolan, F., McDougall, K., de Jong, G., & Hudson, T. (2006). 'A Forensic Phonetic Study of 'Dynamic' Sources of Variability in Speech: The DyViS Project'.
In: P. Warren & C.I. Watson (eds.). Proceedings of the 11th Australasian International Conference on Speech Science and Technology, 6-8 December 2006, Auckland: Australasian Speech Science and Technology Association, 13-18. [pdf]
Conference presentations
de Jong, G., Nolan, F., McDougall, K., & Hudson, T. (2009). 'Vowel space and within-speaker variability.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Cambridge, 2-5 August 2009.
Duckworth, M., Ellis, L., McDougall, K., & Hudson, T. (2009). 'The role of fluency disruptions in characterising speakers.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Cambridge, 2-5 August 2009.
Hudson, T., McDougall, K., de Jong, G., & Harrison, P. (2009). 'F0 trends within and between young, male speakers of SSBE.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Cambridge, 2-5 August 2009.
Hughes, V., McDougall, K., & Foulkes, P. (2009). 'Diphthong dynamics in unscripted speech.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Cambridge, 2-5 August 2009.
de Jong, G., Hudson, T., McDougall, K., & Duckworth, M. (2008). 'Vowel reduction patterns in spontaneous speech'. Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Lausanne, 20-23 July 2008. [abstracts booklet]
de Jong, G., Nolan, F., & McDougall, K. (2008). 'Sound change and within-speaker variability.' Paper presented at the British Association of Academic Phoneticians Colloquium, Sheffield, 31 March - 2 April 2008.
de Jong, G., McDougall, K., Nolan, F., & Hudson, T. (2007). 'The speaker-discriminating power of within-speaker behaviour: a study based on vowel formants.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Plymouth, 22-25 July 2007. [abstract][presentation]
Duckworth, M., McDougall, K., de Jong, G., & Shockey, L. (2007). 'The reliability of formant measurements in high quality audio data: the effect of agreeing measurement procedures.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Plymouth, 22-25 July 2007. [abstract][download presentation 3.0MB]
Hudson, T., de Jong, G., McDougall, K., Harrison, P., & Nolan, F. (2007). 'F0 statistics for spontaneous British English.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Plymouth, 22-25 July 2007. [abstract][download presentation 3.4MB]
McDougall, K. (2007). 'Distinguishing speakers using formant dynamics in read and spontaneous speech: a study of British English /u:/.' Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Plymouth, 22-25 July 2007. [abstract][presentation]
McDougall, K., & de Jong, G. (2007). 'Sound change and the individual: an acoustic study of Standard Southern British English vowels.' Paper presented at the 6th UK Language Variation and Change Conference, Lancaster, 11-13 September 2007. [abstract]
McDougall, K. (2006). 'Characterisation of individuals' formant dynamics using polynomial equations'.
Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Gothenburg, 23-26 July 2006. [abstract][presentation]
McDougall, K. (2006). 'The effects of stress and neighbouring vowel on speaker-distinguishing properties of /r/ in SSBE.'
Paper presented at the British Association of Academic Phoneticians Colloquium, Edinburgh, 10-12 April 2006. [abstracts booklet]
Nolan, F., de Jong, G., & McDougall, K. (2006). 'Introducing the DyViS project: 'Dynamic variability in speech: a forensic phonetic study of British English'.
Paper presented at the British Association of Academic Phoneticians Colloquium, Edinburgh, 10-12 April 2006. [abstracts booklet]
Nolan, F., de Jong, G., McDougall, K., & Hudson, T. (2006). 'Diachronic change as a source of speaker idiosyncrasy: a study of Standard Southern British English monophthongs'.
Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Gothenburg, 23-26 July 2006. [abstract][presentation]
Nolan, F., McDougall, K., de Jong, G., & Hudson, T. (2006). 'Introducing DyViS: a dynamic study of British English for forensic purposes'.
Paper presented at the International Association for Forensic Phonetics and Acoustics Annual Conference, Gothenburg, 23-26 July 2006. [abstract][presentation]
Other publications
McDougall, K. (2007). 'Can a voice identify a criminal?' In: L. Walsh (ed.). Research Horizons. University of Cambridge, Issue 4 Autumn 2007: 24-25. [web version]
'Theoretical issues and empirical studies on the concept of "idiolect" in forensic phonetics.'
Dr Michael Jessen
Federal Criminal Police Office of Germany (Bundeskriminalamt, Wiesbaden)
10 May 2006, 4.15 pm
GR-04 Faculty of English
'Pressure points: how witnesses come to agree with what they do not believe'
Professor John Gibbons
University of New South Wales
Thursday 21 September, 4pm
Room GR05, English Faculty Building, Sidgwick Site